O que é o Apache Iceberg?
O Apache Iceberg é um formato de tabela de código aberto projetado para conjuntos de dados complexos e de grande escala que chegam aos petabytes. Originado como uma solução para gerenciar tabelas massivas com eficiência na Netflix, foi transformado em software de código aberto na Apache Incubator em 2018 e se graduou em 2020.
O Apache Iceberg surge como um formato sofisticado de tabela aberta que funciona como elo de ligação entre os mecanismos computacionais de query e processamento (como Flink e Spark) e formatos de armazenamento de arquivo (como ORC, Parquet e Avro). Se imaginarmos três camadas e numerarmos de 1 a 3 de baixo para cima, teríamos os arquivos de dados (como ORC, Parquet e Avro) na camada 1. Já Apache Iceberg atuaria como middleware que abstrai a complexidade dos formatos de armazenamento de dados na camada 2. Os mecanismos computacionais de query e processamento (como Flink, Spark, StarRocks) estariam na camada mais acima de número 3. Numa camada 4 estariam as ferramentas de business intelligence como Qlik Sense, PowerBI, Tableau, Apache Superset ou Metabase.
Esse design permite operações de dados flexíveis e gerenciamento de esquema em diferentes ambientes de computação sem vinculação a nenhum mecanismo de armazenamento específico, permitindo a livre escolha em hospedar os dados no mecanismo de sua preferência como HDFS, S3, OSS e muitos outros.
Quais são os componentes da arquitetura Iceberg?
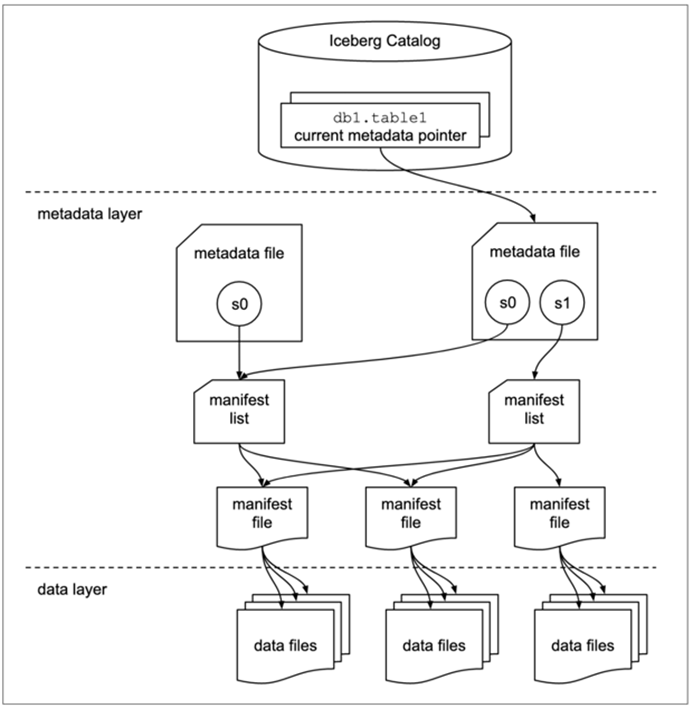
O Iceberg emprega uma abordagem em camadas para o gerenciamento de dados, sendo uma a camada de gerenciamento de metadados e outra a camada de armazenamento de dados.
Camada de dados: Esta camada contém os arquivos de dados reais, como arquivos Parquet e ORC, que são os suportes físicos para armazenar dados.
Camada de metadados: A camada de metadados no Iceberg é multiníveis e é responsável por armazenar a estrutura da tabela e as informações de indexação dos arquivos de dados.
Camada de catálogo: essa camada armazena ponteiros para os locais dos arquivos de metadados, servindo como um índice para os metadados. O Iceberg fornece várias implementações de catálogo, como:
- HadoopCatalog: usa diretamente os diretórios do sistema de arquivos do Hadoop para gerenciar informações de tabela.
- HiveCatalog: armazena metadados de tabela no metastore do Hive, facilitando a integração com o ecossistema do Hive existente.
O gerenciamento de metadados é dividido em três componentes principais:
- Arquivo de metadados: armazena os metadados da versão atual, incluindo todas as informações do snapshot.
- Snapshot: Representa uma “fotografia” instantânea de uma operação específica, com cada commit gerando uma nova “fotografia” instantânea contendo vários manifestos detalhando os endereços dos arquivos de dados gerados.
- Manifesto: lista os arquivos de dados associados a uma “fotografia” instantânea, fornecendo uma visão abrangente da organização dos dados e facilitando a recuperação e modificação eficientes de dados.
Em sua essência, o Iceberg visa rastrear todas as alterações em uma tabela ao longo do tempo por meio de “fotografias” instantâneas, que representam coleções completas de arquivos de dados de tabela em qualquer momento específico no tempo. Cada operação de atualização gera uma nova “fotografia” instantânea, garantindo a consistência dos dados e facilitando a análise de dados históricos e leituras incrementais.
Principais aspectos do formato de tabela Iceberg
Partição oculta
- Partições ocultas: o Iceberg permite que os usuários organizem partições de dados com base em carimbos de data/hora com diferentes granularidades (por exemplo, ano, mês, dia ou hora). As informações de partição são transparentes para os usuários.
- Uso de sintaxe: Use a sintaxe abaixo para criar partições com base em carimbos de data/hora diários. Novos dados são colocados automaticamente nas partições correspondentes.
CREATE TABLE catalog.MyTable (
…, selo_tempo TIMESTAMP)
PARTITIONED BY days(selo_tempo)
Evolução do esquema
- Evolução de esquema flexível: o Iceberg fornece recursos flexíveis de evolução de esquema, suportando operações DDL, como adicionar, excluir, renomear e atualizar colunas.
- Atualizações de metadados: as alterações de esquema apenas atualizam metadados sem reescrever ou mover arquivos de dados. Cada alteração é registrada nos metadados, garantindo que os esquemas históricos possam ser rastreados e consultados.
- IDs de coluna exclusivos: cada coluna na tabela é rastreada com um ID de coluna exclusivo, garantindo a exatidão das operações de leitura e gravação nos arquivos.
Evolução da partição
- Modificação da estratégia de partição: Ao modificar estratégias de partição, os arquivos de dados existentes mantêm sua estratégia de partição original, enquanto novos dados aplicam a nova estratégia.
- Metadados de partição histórica: os metadados registram todas as informações históricas do esquema de partição.
- Planos de execução: O Iceberg pode gerar diferentes planos de execução para lidar com dados envolvendo diferentes estratégias de partição.
MVCC (Multi-Version Concurrency Control)
- Mecanismo MVCC: garante que as gravações de dados não interfiram nas operações de leitura. Cada leitura acessa o instantâneo de dados mais recente.
- Operações de Delete e Overwrite: modificam o status dos arquivos Parquet no arquivo de Manifesto em vez de excluir diretamente os arquivos de dados.
Consistência
- Gravações de Dados Simultâneas: dá suporte a gravações de dados simultâneas usando um mecanismo de bloqueio otimista para lidar com conflitos de gravação.
- Gravações baseadas em Instantâneo: as operações de gravação são baseadas no mesmo instantâneo de dados. Se não houver conflitos, ambas as operações podem ser bem-sucedidas; Se houver um conflito, apenas uma operação será bem-sucedida.
Update a nível de LInha: COW e MOR
- COW (Copy on Write): suportado no formato de tabela V1. Atualiza os dados copiando os originais e aplicando alterações à cópia.
- MOR (Merge on Read): suportado no formato de tabela V2. Introduz arquivos de exclusão de posição e arquivos de exclusão de igualdade para executar exclusões lógicas, refletindo o estado mais recente durante as leituras de dados.
- Exclusão de Posição: registra a posição das linhas de dados a serem excluídas, adequado para cenários em que os dados são alterados com pouca frequência.
- Exclusão de Igualdade: salva o valor dos dados a serem excluídos e executa a exclusão por meio de comparação durante as leituras.
Deixe um comentário