O Parquet é um formato de armazenamento colunar otimizado para consulta analítica e processamento de dados. Os dados de cada coluna são compactados usando uma série de algoritmos antes de serem armazenados, evitando o armazenamento de dados redundantes e permitindo que as consultas envolvam apenas as colunas necessárias. Isso melhora significativamente a eficiência da consulta.
O Apache Parquet, a implementação de código aberto amplamente adotada, foi iniciada pelo Twitter e pela Cloudera e se formou na incubadora Apache como um projeto de nível superior em maio de 2015. Ele suporta formatos de dados aninhados, inspirados no artigo Dremel do Google, permitindo armazenamento e consulta eficientes de estruturas de dados complexas.
Como funciona o Parquet e por que é tão rápido?
Para entender como o Parquet funciona, vamos usar uma tabela de dados simples de comércio eletrônico como exemplo:
| pedido_id | produto_nome | categoria | preco | data_compra |
| 1 | Laptop | Electronics | 999.99 | 1/1/2023 |
| 2 | Smartphone | Electronics | 699.99 | 1/2/2023 |
| 3 | Coffee Maker | Kitchen | 49.99 | 1/3/2023 |
Comparando o Parquet com o Armazenamento Orientado à Linhas
Antes de se aprofundar no Parquet, é útil entender como funcionam os formatos tradicionais de armazenamento orientados a linhas, como CSV ou JSON. Nesses formatos, os dados são armazenados linha por linha. Por exemplo, armazenar a tabela acima em CSV seria assim:
pedido_id,produto_nome,categoria,preco,data_compra
1,Laptop,Electronics,999.99,2023-01-01
2,Smartphone,Electronics,699.99,2023-01-02
3,Coffee Maker,Kitchen,49.99,2023-01-03
No armazenamento orientado a linhas, os dados de cada linha são armazenados em um bloco contíguo, facilitando a leitura e a gravação de registros inteiros. Essa abordagem é adequada para cargas de trabalho transacionais em que as operações normalmente envolvem inserções, atualizações ou exclusões de registros individuais.
Estrutura Multinível do Parquet e estrutura de arquivos
Parquet é um formato de armazenamento colunar que organiza dados em vários níveis hierárquicos: grupos de linhas, colunas e páginas. Essa estrutura melhora o desempenho e a eficiência para tarefas de processamento de big data.
HDFS Block
Um bloco HDFS (Hadoop Distributed File System) é a menor unidade de armazenamento no HDFS. Cada bloco é armazenado como um arquivo local no sistema de arquivos e várias réplicas são mantidas em diferentes máquinas. Normalmente, os tamanhos de bloco são 256 MB ou 512 MB.
HDFS File
Um arquivo HDFS inclui dados e metadados, distribuídos em vários blocos. Cada arquivo no HDFS consiste em vários blocos, que são as unidades fundamentais de armazenamento e replicação.
Grupos de Linhas
Um grupo de linhas é a maior unidade de dados em um arquivo Parquet. Ele divide a tabela inteira em blocos, cada um contendo um número configurável de linhas. Por exemplo, considere uma tabela de comércio eletrônico dividida em dois grupos de linhas, cada um contendo diferentes conjuntos de linhas. O tamanho dos grupos de linhas afeta significativamente o desempenho:
- Grupos de Linhas Maiores: Oferecem melhor compactação e operações de E/S mais eficientes, mas podem aumentar a quantidade de dados lidos ao consultar subconjuntos. O Parquet recomenda grupos de linhas com tamanhos entre 512 MB e 1 GB com o objetivo de alinhar com os tamanhos de bloco do HDFS para um desempenho ideal.
- Grupos de linhas menores: Melhora o desempenho da consulta para linhas específicas, mas pode reduzir a eficiência da compactação.
Os tamanhos típicos de grupo de linhas em implementações do Parquet são de cerca de 128 MB por padrão, mas podem ser ajustados com base no caso de uso específico. Cada grupo de linhas é carregado inteiramente na memória durante as operações de leitura. Para esquemas com tamanhos de registro menores, mais linhas podem ser armazenadas por grupo de linhas.
Bloco de Coluna
Dentro de cada grupo de linhas, os dados de cada coluna são armazenados em uma coluna separada. Os dados de cada coluna são divididos em páginas, a menor unidade no Parquet. As páginas são onde a codificação e a compactação são aplicadas. Veja como a tabela de comércio eletrônico pode ser armazenada:
- Coluna “pedido_id”: 1, 2, 3
- Coluna “produto_nome”: Laptop, Smartphone, Coffee Maker
- Coluna “categoria”: Electronics, Electronics, Kitchen
- Coluna “preco”: 999.99, 699.99, 49.99
- Coluna “data_compra”: 2023-01-01, 2023-01-02, 2023-01-03
Como as colunas armazenam dados do mesmo tipo juntas, o Parquet pode usar várias otimizações para armazenar esses dados de forma eficiente em formato binário.
Páginas
Cada bloco de coluna é dividido em páginas, a menor unidade de armazenamento no Parquet. As páginas são a unidade básica de codificação e compactação. Páginas diferentes dentro do mesmo bloco de coluna podem usar diferentes técnicas de codificação. Páginas menores permitem acesso mais refinado, mas páginas maiores reduzem a sobrecarga de armazenamento e os custos de análise. Um tamanho de página de 8 KB é normalmente recomendado.
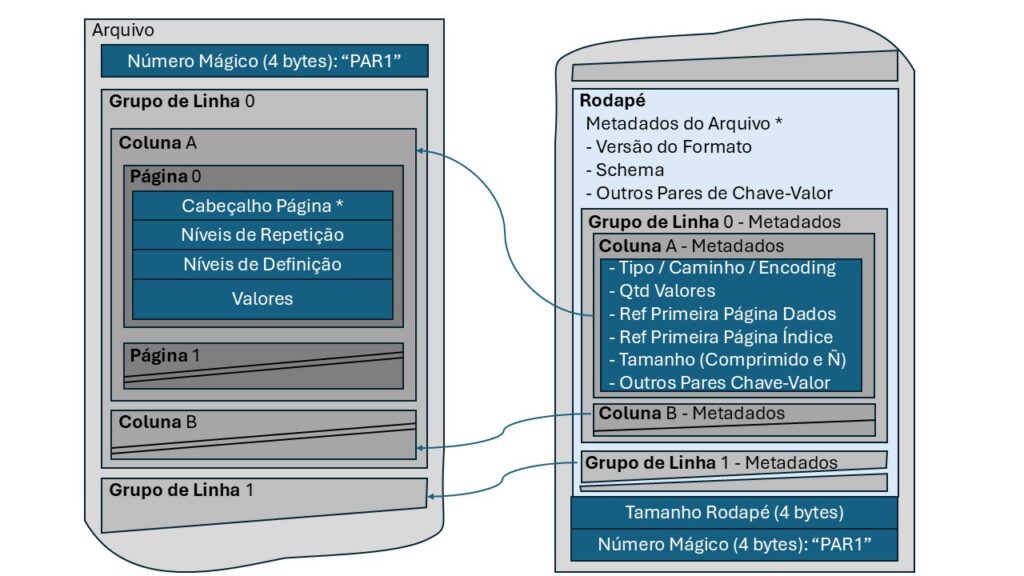
Estrutura de um arquivo Parquet
Um arquivo Parquet consiste em três seções principais: Cabeçalho, Blocos de Dados e Rodapé. Cada arquivo começa e termina com um número mágico “PAR1” para identificá-lo como um arquivo Parquet.
Cabeçalho
O cabeçalho contém o número mágico inicial “PAR1”.
Blocos de Dados
A seção de blocos de dados é onde os dados reais são armazenados. Ele é composto por vários grupos de linhas, cada um contendo um lote de dados. Por exemplo, se um arquivo tiver 1000 linhas, ele poderá ser dividido em dois grupos de linhas, cada um contendo 500 linhas. Dentro de cada grupo de linhas, os dados são organizados por coluna, com todos os dados de uma única coluna armazenados juntos em um bloco de colunas. Cada bloco de coluna é dividido em páginas, classificadas como páginas de dados ou páginas de dicionário. Este design hierárquico permite:
- Carregamento paralelo de vários grupos de linhas.
- Armazenamento e recuperação colunar eficientes por meio de blocos de coluna.
- Acesso a dados refinados por meio de páginas.
Rodapé
O rodapé contém metadados críticos sobre o arquivo. Ele inclui o esquema de arquivo e os metadados para cada grupo de linhas e coluna. O rodapé também inclui o comprimento do próprio rodapé (Comprimento do rodapé) e termina com o número mágico “PAR1” novamente para validação.
A estrutura do rodapé do arquivo inclui:
- Metadados do Arquivo: Descreve o esquema e contém metadados para cada grupo de linhas.
- Comprimento do Rodapé: Um inteiro de 4 bytes que indica o tamanho da seção de rodapé.
- Número Mágico: “PAR1” indicando o fim do arquivo Parquet.
Deixe um comentário