A vetorização no contexto de bancos de dados refere-se ao processo de otimização das operações de banco de dados para aproveitar as arquiteturas modernas de CPU. Isso envolve o processamento de vários elementos de dados em paralelo em um único ciclo de instrução da CPU, aproveitando um método conhecido como SIMD (Single Instruction, Multiple Data).
Isso contrasta com a arquitetura SISD (Single Instruction, Single Data), em que cada instrução lida com um único ponto de dados. No SIMD, as tarefas que, no SISD, normalmente exigiriam várias operações de carregamento, adição e armazenamento, são condensadas, melhorando significativamente o desempenho.
O impacto da vetorização na performance do Banco de Dados
Avaliando o desempenho da CPU no Contexto da Vetorização
Para entender o impacto da vetorização, é essencial entender a medição do desempenho da CPU e os fatores de influência. A fórmula para o tempo de CPU é um ponto de partida:
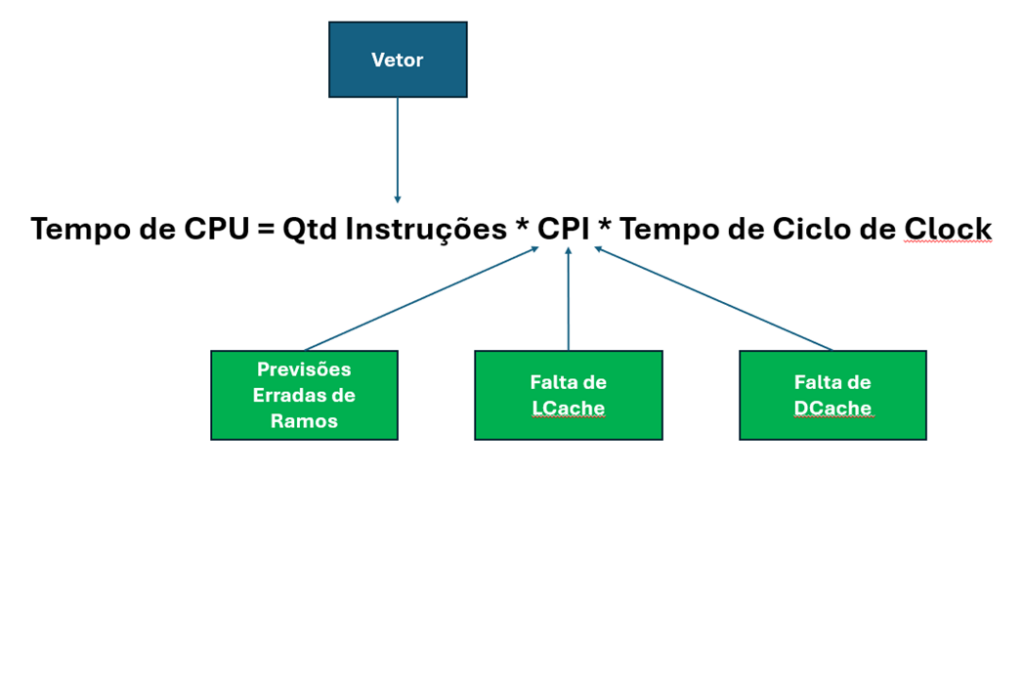
Aqui, ‘Qtd de Instruções’ representa o total de instruções que a CPU processa, ‘CPI’ (Ciclos Por Instrução) significa os ciclos de CPU necessários para cada instrução e ‘Tempo de Ciclo de Clock’ é a duração de um ciclo de clock da CPU. Como alterar o tempo do ciclo do clock não é viável, focar nos números de instrução e no CPI é fundamental para melhorar o desempenho do software.
Execução de Instruções de CPU e Vetorização
A execução da instrução da CPU compreende cinco etapas: busca, decodificação, execução, acesso à memória e write-back de resultados. As duas primeiras etapas são gerenciadas pelo front-end da CPU, enquanto as três últimas são tratadas pelo back-end da CPU.
Os problemas de desempenho surgem principalmente da desativação, especulação ruim, limite de front-end e limite de back-end, geralmente atribuídos à otimização insuficiente de instruções SIMD, erros de previsão de ramificação e erros de cache.
Programas de Vetorização: Métodos e Verificação
A vetorização pode ser implementada de várias maneiras, cada uma variando em complexidade e envolvimento do programador:
- Vetorização automática por Compilador: Não requer alterações de código. O compilador converte automaticamente o código escalar em código vetorial.
- Dicas para o Compilador: Fornecer dicas aprimora a capacidade do compilador de gerar código SIMD.
- APIs de Programação Paralela: ferramentas como OpenMP ou Intel TBB permitem que os desenvolvedores adicionem anotações para gerar código vetorial.
- Bibliotecas de classes SIMD: Essas bibliotecas facilitam o uso de instruções SIMD.
- Funções em Assembler para SIMD: Essas são funções codificadas em assembly que permitem o uso de chamadas de função C++ para SIMD.
- Escrevendo código Assembler diretamente: Este método exige alta experiência em programação.
Para verificar a vetorização, pode-se usar as opções do compilador para obter feedback ou revisar o código em Assembler executado para registros e instruções SIMD.
Superando os desafios da Implementação da Vetorização de Banco de Dados
A vetorização de banco de dados não se trata apenas de ativar os recursos do SIMD. Isso envolve uma revisão abrangente da arquitetura de banco de dados, incluindo:
- Dados Colunares de ponta a ponta: Requer armazenamento, transferência e processamento de dados em formato colunar para eliminar a incompatibilidade de jornada de dados.
- Vetorizando todos os componentes: Todos os operadores, expressões e funções de banco de dados precisam ser vetorizados.
- Otimizando para uso de instruções SIMD: Isso envolve otimização detalhada para invocar instruções SIMD.
- Gerenciamento de Memória: Repensando o gerenciamento de memória para aproveitar totalmente os recursos de processamento paralelo do SIMD.
- Desenvolvendo novas Estruturas de Dados: Os operadores principais, como Join, Aggregate e Sort, precisam ser projetados desde o início para oferecer suporte à vetorização.
- Otimização Sistemática: A otimização abrangente de todos os componentes do sistema de banco de dados é necessária para melhorias significativas de desempenho.
Estratégias para Maximizar o desempenho do Banco de Dados com vetorização
A vetorização de bancos de dados é um extenso processo de engenharia, e o StarRocks serve como um excelente exemplo. Nos últimos anos, inúmeras otimizações foram aplicadas no desenvolvimento do StarRocks. As principais áreas de foco para essas otimizações incluem:
- Utilização de bibliotecas de terceiros de alto desempenho: Aproveitar poderosas bibliotecas de código aberto para estruturas de dados e algoritmos é crucial. Bibliotecas como Parallel Hashmap, Fmt, SIMD Json e Hyper Scan têm sido fundamentais nesse sentido.
- Otimização de Estruturas de Dados e Algoritmos: Estruturas de dados e algoritmos eficientes desempenham um papel significativo na redução substancial dos ciclos da CPU. Por exemplo, a introdução de um dicionário global de baixa cardinalidade em versões mais recentes do banco de dados permitiu a transformação de operações baseadas em strings em operações baseadas em inteiros mais eficientes, levando a uma melhoria de mais de 300% no desempenho da consulta.
- Otimização Auto-adaptativa: Isso envolve otimizar a execução da consulta com base no seu contexto específico, que geralmente não é totalmente conhecido até o tempo de execução. O mecanismo de consulta ajusta dinamicamente sua estratégia com base em informações de contexto em tempo real, melhorando assim o desempenho.
- Otimização estratégica de SIMD: A implementação de uma variedade de otimizações SIMD em operadores e expressões de banco de dados é uma etapa crítica. Esse processo envolve o ajuste fino de várias funções de banco de dados para se alinhar aos recursos do SIMD.
- Otimização C++ de baixo nível: Diferentes implementações de C++, mesmo com estruturas de dados e algoritmos idênticos, podem produzir resultados de desempenho variados. As otimizações podem incluir ajustes em operações de movimentação ou cópia, reserva de vetores ou chamadas de função embutidas.
- Aprimoramento do Gerenciamento de Memória: À medida que os tamanhos dos lotes aumentam e as operações se tornam mais simultâneas, a alocação e o gerenciamento eficientes de memória tornam-se mais críticos. Soluções inovadoras, como o uso de uma estrutura de dados de pool de colunas, foram desenvolvidas para melhorar a utilização da memória, aumentando significativamente o desempenho da consulta.
- Otimização de cache de CPU: Os erros de cache da CPU afetam significativamente o desempenho, medido no aumento dos ciclos de CPU necessários para o acesso à memória em diferentes níveis de cache. Depois de implementar a otimização SIMD, lidar com erros de cache da CPU por meio de métodos como pré-busca torna-se essencial, embora seja um desafio controlar seu tempo e distância de forma eficaz.
Em resumo, a vetorização de banco de dados é um empreendimento multifacetado, exigindo uma combinação de técnicas avançadas e otimizações em vários aspectos da arquitetura e programação de banco de dados. Essas melhorias contribuem coletivamente para melhorar significativamente o desempenho do banco de dados, demonstrando o poder da vetorização em sistemas de banco de dados modernos.
Vetorização: o futuro do desempenho dos Banco de Dados
- Uma abordagem holística para o desempenho: conseguir criar bancos de dados de alto desempenho por meio da vetorização requer uma combinação de arquitetura bem pensada e engenharia detalhada. Esse equilíbrio é crucial para maximizar os benefícios da vetorização de banco de dados.
- Explorando além das CPUs tradicionais: O futuro do desempenho do banco de dados pode estar na exploração de novas fronteiras de hardware, como GPUs e FPGAs, para expandir ainda mais os limites da vetorização de banco de dados.
- O poder da Comunidade e da Inovação: Projetos como o StarRocks mostram o imenso potencial do desenvolvimento orientado pela comunidade para melhorar o desempenho do banco de dados. O impulso constante em direção à inovação e o desafio ao status quo levaram a avanços significativos no campo da vetorização de banco de dados.
Conclusão
A vetorização é um fator-chave na evolução contínua da tecnologia de banco de dados, oferecendo um caminho para melhorias drásticas de desempenho. À medida que os volumes de dados e as demandas de processamento aumentam, entender e implementar a vetorização se torna cada vez mais crítico. Adotar essa tecnologia é essencial para quem busca se manter na vanguarda do desempenho e da eficiência do banco de dados.
Deixe um comentário